UDP, ICMP, IP 协议校验和的计算
最近在实现一个简单的 udp 协议栈, 几乎每一层的协议都要计算校验和. 总结一下校验和计算的过程, 也希望对他人有用.
1. 校验范围
虽然每个协议里都有校验和字段, 但是每个校验和覆盖的范围都是不同的:IP 协议: 只包含 20 字节的 IP 报头
ICMP 协议: 整个 ICMP 报文 (ICMP 报头 + ICMP 数据)
UDP 协议 / TCP 协议: 除了整个 UDP/TCP 报文以外, 前面再加上一个 12 字节的伪 IP 报头. 对这个整体一起算校验和 (见下图)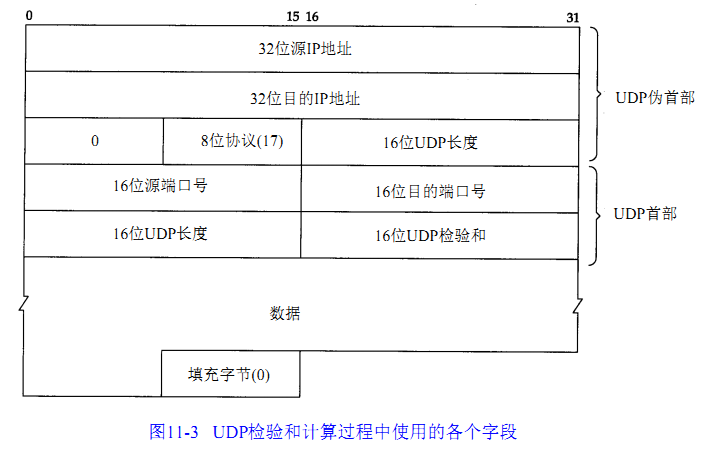
图 from:TCP/IP 详解
另外, 如果接收到的 UDP 校验和为 0, 则说明不要进行校验和计算
2. 计算步骤
发送时:将校验和字段置零
对校验范围逐 16bit 做反码和
得到的和即为校验和
接收时:
对校验范围逐 16bit 做反码和
若校验和为 0 则正确, 否则错误
3. 如何计算
反码: 这里的反码指的是对原来的数所有位二进制取反, 既: unsigned int A 的反码为~ A对每个数求反码然后相加, 如果最高位有进位则加到最低位 (循环进位)
如果是奇数个字节, 将最后一个字节 (设为 Z) 扩展成: [Z, 0x00]
由上面简单的解释, 我们可以写出一个最直观的算法, 本人自己写了一个, 感觉太烂了就不放出来了.
4. 优化
事实上, 我们一直没提到二进制反码和的优点, 在 RFC1071 中详细的提到了反码和具有的数学上的优点, 利用这些, 可以有效加快校验和的计算:在计算时先求反再相加和先相加再求反结果一致
延迟进位 (在 32 比特加法器中进行 16 比特求和,这样溢出就被放到了高 16 位中。这种方法可以避免使用进位敏感指令但需要两倍于在 32 比特寄存器相加的加法运算。速度提高取决于具体的硬件体系。)
字节顺序无关
第二点对于 32 位机很好, 但是在 8 位单片机上就有点…
然后, 在 RFC1071 中还给出了一个利用了这些优化的 C 示例:
1 | static unsigned short checksum(unsigned short* data, int size) |
作者使用一个 32 位的 sum 来保存计算结果. 11 行是处理奇数个数据的. 最后一个循环是把进位加到低位上.
看到这么好的实现, 我也放弃用我自己写的了, 干脆用这个. 另外, stm32 中有一个硬件实现的 CRC 模块. 下次移植到 stm32 上的时候用用它试试.