最近在读一本书《大型网站技术架构》,收获颇多。这篇文章是对最近学习的一些总结,大多是一些结论性的内容,可以拿来就用的东西,对于大部分企业都比较适用。注意这些内容并不是我自己发明的,而是业界多年来的经验总结出的结论。
高性能
1. 性能测试
保证网站高性能的前提是做性能测试,如果连网站的性能指标都不知道,怎么判断一个网站“慢不慢”和“高性能”呢。
对一个网站做性能测试时,主要需要测试一下几项数据:
- 并发数
- 响应时间
- 吞吐量(TPS,每秒事物数)
- 资源消耗(主要指cpu、内存消耗)
在做性能测试时,一般以并发数为自变量,逐步提高并发数,每次记录上述四个指标,制作出一张表格以方便后面进行分析。
例子如下:
| 并发数 | 响应时间 | TPS | 出错率 | CPU | 内存 | 备注 |
|---|---|---|---|---|---|---|
| 100 | 10ms | 200 | 0% | 5% | 200MiB | 性能测试 |
| 200 | 15ms | 266 | 0% | 10% | 300MiB | 性能测试 |
| 300 | 20ms | 300 | 2% | 15% | 400MiB | 性能测试 |
| 400 | 50ms | 330 | 20% | 35% | 600MiB | 负载测试 |
| 500 | 100ms | 350 | 25% | 40% | 800MiB | 负载测试 |
| 600 | 500ms | 360 | 30% | 50% | 1.0GiB | 压力测试 |
| 700 | 1200ms | 350 | 50% | 60% | 1.5GiB | 压力测试 |
| 800 | timeout | 0 | 100% | N/A | N/A | 压力测试 |
看表格不是很直观,我简单解释一下。这个测试大致分为三个stage:性能测试、负载测试、压力测试。
- 性能测试:网站正常运行的状态。随着并发数量的增大,响应时间不会有很大的变化;吞吐量和资源消耗基本上时线性正相关。
- 负载测试:网站某项或多项性能指标已达到临界值。此时增大并发数量响应时间已经有明显的影响;资源消耗增大而吞吐量不会有太大变化。
- 压力测试:已超出安全负载。此时响应延迟明显增大;资源消耗越来越多而系统吞吐量不增反降。继续增大负载,系统将崩溃,不能接受任何请求。
分别以 “资源消耗” 为横轴、TPS 为纵轴画出函数图像可以更直观的观察两者之间的关系。
分别以 “并发数” 为横轴、“响应时间” 为纵轴,观察两者关系。
通过以上分析,判断一个网站是否高性能,可以通过并发数来做基本的判断。更准确的应当通过上图中的b点处(系统最佳运行点)的并发数量来判断网站性能。
2. 前端性能优化
这部分和我们讨论的网站架构关系不大,对于后端开发者来说需要注意的点有:使用CDN、注意开启浏览器缓存、合并JS减少HTTP请求等等,主要还是靠前端工程师的努力啦。
3. 应用性能优化
对于应用层的性能优化主要有三种方法:加缓存、使用异步操作、应用集群化。这三者越靠前者越应当优先使用,效果越好,对系统影响越小。
分布式缓存
有一位计算机科学家曾说“缓存是最伟大的发明”,在系统中使用缓存可以挡住大部分请求从而可以不访问数据库。但是并不是说缓存可以在任何地方使用(滥用)。使用缓存有以下原则。
- 不应缓存频繁更改的数据。一般来说,缓存是被用来读的,如果一个缓存刚刚写入没过过久又被修改了,这样毫无意义。最好的情况是,缓存写入后被读了成千上万次。
- 应缓存热点数据。缓存使用内存存储,如果将不频繁访问的数据放入缓存的话太浪费内存空间。
- 注意数据不一致问题。缓存一般设置超时时间,当用户修改了数据后缓存不一定能及时更新。应根据业务合理设置超时时间。
- 注意缓存可用性问题。应妥善结果缓存挂了的情况,因为数据库已经习惯了有缓存的“舒适”的日子,一旦缓存挂了之后数据库压力山大而宕机导致网站整体不可用。
- 应进行缓存预热。当换上一台新缓存服务器后不应立即撤掉老的缓存服务器,因为新机器内部还没有任何数据,大部分访问还是会打到数据库。所以新的缓存服务器启动时最好将热点数据提前载入进行预热。
具体在使用缓存时可以使用业界通用的开源缓存系统,如redis、memcached、jboss cache等。
异步操作
网站一些操作可以不直接访问数据库,而是将任务放入消息队列异步化。是用另一台 consumer 服务器从消息队列中取出任务进行数据库访问。
这样可以有效的起到“削峰”作用。经常用于应对突然增加的并发数,比如在抢购系统中,在前几分钟会接到很多请求,将这些请求放入消息队列中逐个处理,当处理结束后再使用 websocket 等通知方式告知用户是否抢购到商品。
应用集群化
使用负载均衡技术,在网站入口搭建一台负载均衡服务器(如nginx),入口后搭建一个应用服务器集群,当接收到请求后,负载均衡服务器使用一定算法将请求平均的打到不同的应用服务器上。
这样,比如应用集群有10台机器,那么理想状态下每台机器的负载只有总负载的 1/10 。
4. 存储性能优化
先略过不表
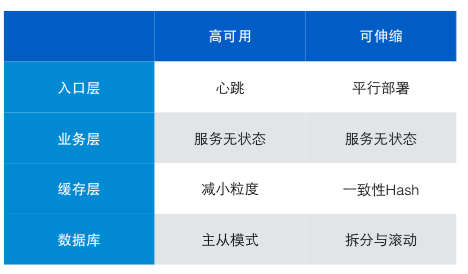
高可用
可用性指网站的故障情况。网站的故障时间越短,故障范围越小说明网站可用性越高。对于网站提高网站的可用性,需要从四方面入手:负载均衡(入口)、应用、缓存、数据库。
1. 入口层
需要在 nginx 挂了之后还有机器能顶上。可使用的技术有 VRRP,具体说来就是当一台机器挂了之后,另一台机器检测到了之后立即把自己的IP地址设置为原有机器的IP地址。通过这种抢地址的方式来接管新的请求。
2. 应用层
应用层做到高可用的方式就是“集群化”。部署多台应用服务器,对于负载均衡来说每台业务服务器都是一样的,当一台机器挂了之后将请求打到其他机器上就好了。
做应用集群化的核心就是“业务层不要有状态”。将状态保存到缓存层和数据库中。以下几点是大家常犯的错误:
- session数据,很多语言都自带了 session 功能(如php)。这样不利于集群化,所以在写代码时应注意不要使用语言自带的 session 系统,最好将 session 数据存储到缓存层、另外也可以使用 CookieSession ,将 session 加密存储在客户端。
- 缓存,很多程序员喜欢在业务层使用一个全局的 map 缓存一些数据,这样就不必频繁访问数据库了,但是在使用集群时很容易造成不同机器上的缓存数据不一致的问题。这样从缓存拿到的数据就是错误的。
- 全局变量。写代码时不要使用全局变量。
3. 缓存层
现在普遍使用缓存,因为缓存可以替 mysql 挡住大部分请求。所以这种情况下,整个系统都过于依赖缓存层。因为一旦缓存不可用之后,所有的请求都打到数据库上,导致数据库压力过大。
因此,保证缓存层高可用也是必要的了。达到缓存层高可用的方式也是集群化,将缓存分的细一些,不同的数据存储到不同的 cache 中。这样某一个 cache 宕机之后不至于太过严重。
4. 数据层
数据层有一个经典的原理,叫做 CAP 原理。CAP 分别指:一致性( C onsistency)、可用性(A vailibility)、分区耐受性(P atition Tolerance)。
CAP 原理认为,一个数据服务通常无法同时做到以上三点。所以一般情况下网站会舍弃一致性,而达到可用性和分区耐受性(既可伸缩性)。
数据层做高可用的主要技术是:数据备份。
数据备份主要分为:热备、冷备。
冷备指定期对数据库进行备份,如果发现数据库出错了会滚到上一个备份。这种方式其实做不到数据最终一致。
热备主要分为同步热备和异步热备。
- 同步热备指同时开两个数据库,应用在读写时同时对两个数据库进行操作,这样当一个数据库宕机之后另一个数据库中还保存完整数据。
- 异步热备一般指 Master-Slave 模式,应用只对 master 进行写入操作,master 会随后将数据同步到 slave 中。
这两种功能 mysql 都有实现。
可伸缩
可伸缩性指当业务达到负载上限时,可通过简单的增加机器的方式提高系统的负载能力。
1. 入口层
可以通过 DNS 来实现,目前 DNS 服务器会使用轮转算法返回 IP 地址,这样就可以把请求分配到不同的负载均衡上。
2. 应用层
其实应用层做到可伸缩性和高可用的解决方案一致,都是集群化,核心都是保证应用无状态。
3. 缓存层
缓存要保证水平扩展的同时不增加额外的消耗需要一些技术。常见的技术是一致性 HASH。可以保证水平扩展后较少的数据失效。
4. 数据层
数据库层做可伸缩的话常用的技术就是分库、分表。
书中也介绍了一些开源的技术如 Cobar 之类的,不过我没有去深入研究。
总结
网上找了张图,总结的不错。