lua 语言最大的卖点之一就是他的协程(coroutine)了。但是在 lua5.1 中有一个文档都没提到的一个坑:协程只能在 lua 中使用,当调用 yield 时,如果当前的调用栈上有 c 代码,则会报错 “attempt to yield across metamethod/C-call boundary”。目前有个第三方的 patch 叫做 luaCoco 可以让 lua 支持 “真协程”。本文研究了 luaCoco 的内部实现,并把它移植到了 xtensa 处理器上。

[toc]
setjmp 的实现
在文章的开头需要先讲解一下c语言标准库中 setjmp 的内部实现,因为之后的 luaCoco 的实现就是对 setjmp 的数据结构的一个 hack。
先看看 setjmp 的用法
1 |
|
在调用 setjmp 的时候,会返回 0,从而会执行 if (code == 0) { 为 true 的 block,会打印出 before jmp。当执行了 longjmp 之后,程序的执行会重新跳转到 setjmp 那一行(第七行)然而这次 setjmp 的返回值 code 不再是 0,而是 longjmp 的第二个参数(1024),这样就会打印出 jmp here, code: 1024。
利用 setjmp 的这个功能能实现出很多有趣的东西,比如在c语言中做 Exception,但是 setjmp 是怎么实现的呢?我们去读一读源码。
libc 的实现有好多种,常见的比如 glibc、uclibc 和 musl-libc,但是我们这次读一读 newlib 的源码。newlib 也是一个 libc 的实现,常用于嵌入式开发中。
打开 inlcude/machine/setjmp-dj.h 文件,可以看到 jmp_buf 的定义:
1 | // from inlcude/machine/setjmp-dj.h |
发现这个结构体是用来存储 cpu 的寄存器的。这里很好理解,因为要实现 长跳转(longjmp),必须要首先把跳转的目的地的现场先保存下来。
setjmp 函数做的工作就是保存现场:
1 | // from machine/i386/setjmp.S |
看图解释一下代码:
- 17 行:push ebp 到栈上(esp 同时下移 4 字节)
- 18 行:ebp 指向 esp
- 20 行:push edi 到栈上(esp 同时再下移 4 字节)
- 21 行:8(ebp) 保存的是 jmp_buf 的指针,先把它放到 edi 中
- 23 - 27 行:分别把 eax、ebx、ecx、edx、esi 保存到 jmp_buf 里
- 29 - 30 行:-4 (ebp) 是edi,如图
- 32 - 33 行:(ebp) 就是之前的ebp,如图
- 35 - 37 行:保存 esp
- 39 - 40 行:如图,保存
return addr到 jmp_buf->eip
longjmp 的实现是正好相反的:
1 | SYM (longjmp): |
代码就不赘述了,基本上就是恢复现场、把longjmp的第二个参数作为返回值返回(7 - 9 行还有一个判断:如果参数为0的话,会把它改成 1)。
LuaCoco 的实现
首先在看代码之前,先简单讲解一下我对 LuaCoco 的理解。lua 的协程其实也就是为每个协程维护了一个 context(所谓 context,既程序执行到某个地方时的状态,包括寄存器、callstack)。当协程之前相互 yield 的时候,切换一下 context。但是 lua 没做好的地方是 lua 仅保存了 lua 程序的 context,而 c 代码的 context 是没有保存的。这是因为 lua 很追求使用 pure c,不希望在源码中加入过多平台相关的东西。保存 lua 的 context 是比较简单的,因为所有 lua 程序相关的数据结构都放在 lua 虚拟机里,只需要每个 coroutine 保存一份就好了,而取得/保存 c 代码的上下文是需要操作平台相关的寄存器的。LuaCoco 就是为每个常见的平台都做了一份保存 c 程序 context 的实现。
下面看 LuaCoco 的源码。
LuaCoco 是对 lua 源码的一个 patch,coco 改动了 lua 的以下文件:
最主要的文件就是 lcoco.c 和 lcoco.h 了:
我看源码一般喜欢先看一下 header 文件,瞄一眼 coco 大体上做了什么事情。
1 | // from lcoco.h |
lcoco.h 里声明了 coco 定义的 4 个函数。很明显,lua_newcthread 是为了取代原生 lua 中的 lua_newthread 函数的。这一点可以在 lbaselib.c 文件的改动中看到。
1 | // from lbaselib.c |
这里用宏判断了是否开启 coco,如果开启的话就使用新的 lua_newcthread,否则的话还使用原生的 lua_newthread。
那么,下一步就着重来看看 lua_newcthread 的实现。
1 | /* Add a C stack to a coroutine. */ |
先看函数签名,发现比原生的 newthread 多了一个 cstacksize 参数,因为现在需要为 c 程序保存上下文,c 程序的执行需要一个 stack,所以每个 coroutine 都要有一个自己的 stack。这个 cstacksize 参数就是用来控制这个 stack 的大小的。
继续看代码,几个 if 的意思也很清晰,不表。发现重要的功能都封装到了 COCO_NEW 这个宏里面了。再一翻代码,这个宏又套了好几层宏和宏判断,搞得我很郁闷。所以我就使出了我的编译器大法!
1 | gcc -E -DCOCO_USE_SETJMP -D__linux__ -D_I386_JMP_BUF_H -D__i386 lcoco.c > _lcoco.c |
这个命令可以让编译器只执行预处理,说白了就是把 c 语言的宏全部展开。命令中定义的其他几个宏的意思分别是:使用 setjmp 实现协程、使用Linux架构、使用i386架构。
宏展开的结果如下:
1 | lua_State* lua_newcthread(lua_State* OL, int cstacksize) { |
可以看到,主要做的事情就是 alloc 了 coco_State 数据结构和 cstack。这里只申请了一次内存空间,然后通过指针操作分别把内存分成了 coco_State 和 cstack 两块。有点迷糊的可以看一下我画的图:
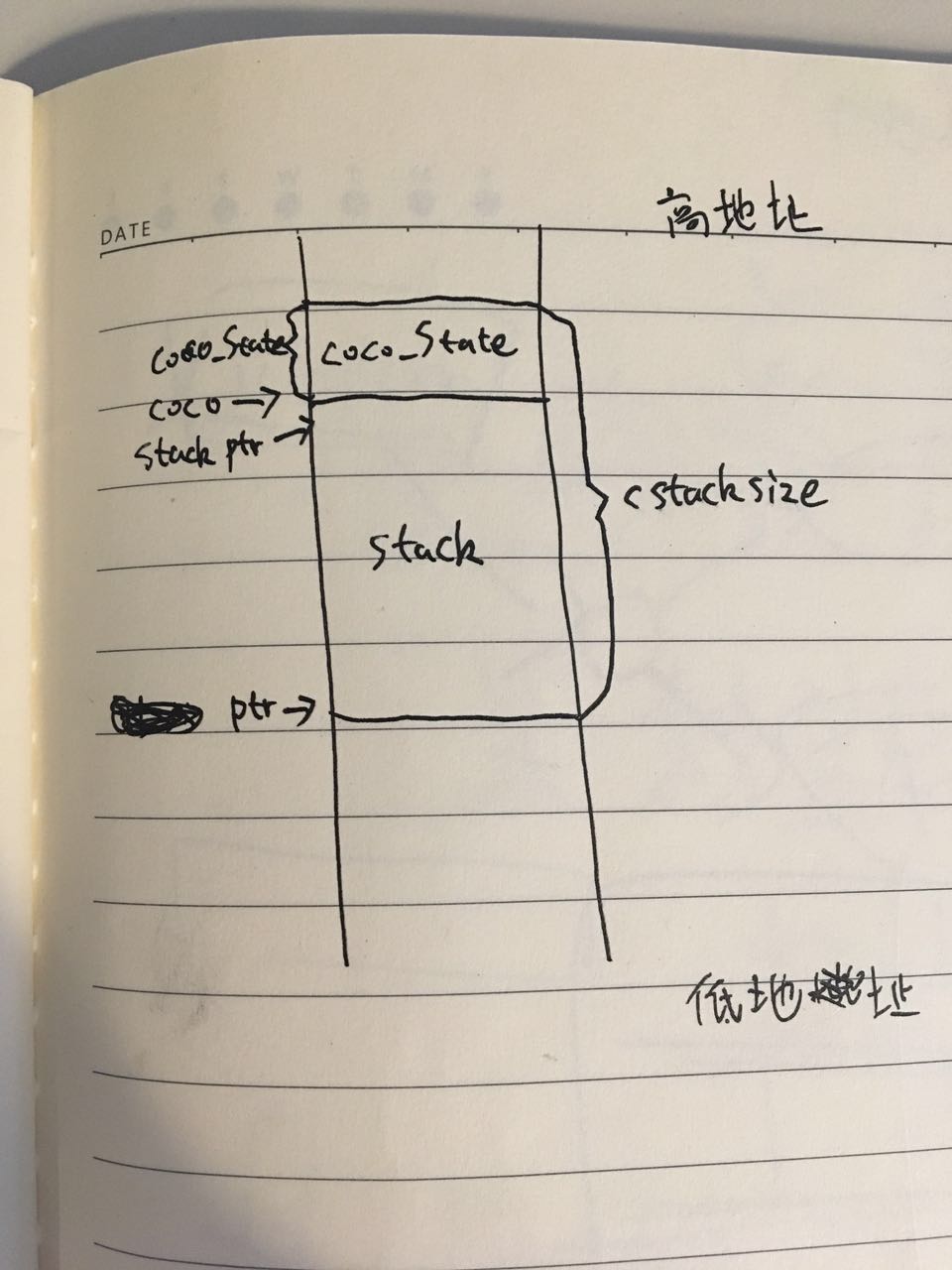
申请好空间之后,11到16行初始化了 coco_State 的几个字段。
17行把 coco 的指针放到了 NL 的前面(我并不知道为什么可以这么做,反正就是可以,看的时候我一脸“还有这种操作?”的黑人问号)
下面我们去看看 coco_State 的代码。
1 | struct coco_State { |
经过宏替换之后,coco_State 长上面这样。
lua_newcthread里的代码初始化了 ctx,allocptr,allocsize,arg0 字段。其中,对 ctx 的初始化操作比较让人在意,首先是调用 setjmp 初始化了 ctx,之后对 ctx 内部的几个字段进行了魔改。
1 | coco->ctx->__pc = (((coco_MainFunc)(coco_main))); |
有了之前 setjmp 的基础,这里就容易理解了,一旦对这个 ctx 调用 longjmp 的话,程序就会跳转到 coco_main 这个函数,并且把 stackptr 当作程序的 stack 来使用。这个 stack 的切换操作,其实就是程序 context 的切换
我们先不看 coco_main 做了什么,先看看这个 longjmp 会在什么时候调用,动脑子想一想,应该会是再执行 resume 的时候调用 longjmp,果然不出所料:
1 | int luaCOCO_resume(lua_State* L, int nargs) { |
在 resume 的时候,首先使用 setjmp 把主线程的状态保存到 coco->back 里,然后调转到 coco_main。
下面看 coco_main 做了什么。
1 | static void coco_main(lua_State* L) { |
main 首先通过L取到了coco的指针(又一次黑人问号)。然后通过 luaD_rawrunprotected 调用了 lua 程序(也就是lua子线程)。之后判断子线程时候出错,设置错误码。最后,保存子线程的状态到 ctx,然后跳转会 back(调转到了luaCOCO_resume 第6行)。
继续回来看 luaCOCO_resume 函数,第 6 行后面宏展开前其实是这样:
1 | if (L->status != LUA_YIELD) { |
展开前的代码比较容易懂:如果子线程执行完了,就 free 掉,没啥可说的。
最后看看 yield:
1 | int luaCOCO_yield(lua_State* L) { |
跳转那里和之前讲的一样,多了的东西没太明白,好像是在复制 lua_State 内部的数据。
LuaCoco 内部实现的内容基本上就这些了。
题外话:其实除了魔改 setjmp,LuaCoco还有三种实现,直接内连汇编、使用ucontext和使用fiber,大家可以通过执行 gcc -E lcoco.c > _lcoco.c 加不同的宏定义来生成代码自行研究(其实原理都差不多)。
xtensa 架构 ABI
这部分就简单讲一下带过了,毕竟不是那么通用的内容。
经常做移植的同学应该大多知道,移植的时候最重要的是需要了解这个 architecture 的 ABI(application binary interface)。Google 一番之后发现了这个pdf,不过先不急着看 ABI,先看一下这个 CPU 的寄存器吧。
xtensa 有 16 个 32 位的通用寄存器,名字分别叫 A0 ~ A15,一个 PC 程序计数器,再加上一个 SAR 寄存器(不知道干嘛用的,不过好像移植的话用不上),还算挺简单的设计,没有奇奇怪怪的东西。
接下来,再看看 xtensa 的 ABI,在 PDF 的 chapter 8 里找到了 关于 Xtensa ABI 的部分。xtensa 使用了两种ABI,一种叫 Windowed Register 另一种叫 CALL0 。NodeMCU 只会用到 CALL0 所以我们简单讲一下 CALL0。
先看表格:
| Register | Use |
| | |
| a0 | Return Address |
| a1 (sp) | Stack Pointer (callee-saved) |
| a2 – a7 | Function Arguments |
| a8 | Static Chain (see Section 8.1.8) |
| a12 – a15 | Callee-saved |
| a15 | Stack-Frame Pointer (optional) |
A0 保存了函数的返回地址,A1保存了栈指针,a2到a7一共6个寄存器用于传递函数的参数,更多的参数会在栈中传递,a12-a15需要被调用者自己保存。
看完了寄存器的使用,看一下 xtensa 的栈帧(stack frame)格式:
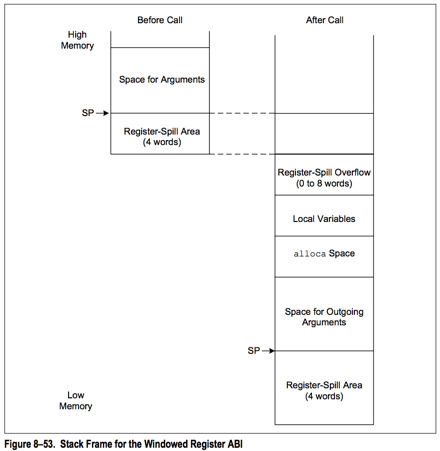
可以看出来,xtensa 的指针也是向低地址方向增长的。在 SP 的上面会保存依次 6个参数以外的参数 、局部变量 等
移植 LuaCoco
搞清楚 ABI 了,最后的工作就是 coding 了。
遇到的第一个问题是,因为我们要对 setjmp 进行 hack,而不是使用汇编,所以我们仅能操作内存,而不能操作寄存器,所以如何将 lua_State 传递给 coco_main 呢?最常见的方法就是使用 哑参数(dummy args)。
1 |
我们把 coco_main 的参数列表定义成这样,前面a到f的参数都是用不上的,这样就不用管 a2 到 a7 这几个寄存器了。所以我们只需要把L指针放到SP指的位置就好了。
1 | #define COCO_PATCHCTX(coco, buf, func, stack, a0) \ |
stack[0] = (size_t)(a0); 这一句中的 a0 就是 lua_State 的指针,把他放到了 SP[0] 这里。
第二个问题就是对 jmp_buf 进行 hack 了,我们需要搞明白 jmp_buf 里怎么放东西的,这需要看这个平台编译器的源码了。https://github.com/pfalcon/esp-open-sdk 这里是编译器的源代码,他是使用 crosstool 的,会一边下载源代码,一遍编译,下载好的源代码放在 crosstool-NG/.build/src/newlib-2.0.0 ,正好我们看看 newlib 中 setjmp 的实现:
1 | #else /* CALL0 ABI */ |
上面的 else 宏代表这段代码是使用 CALL0 ABI 才会被编译。看一下代码,可以了解到以下对应关系:
| jmp_buf | Register | Use |
| | |
| jup_buf[0] | a0 | Return Address |
| jmp_buf[1] | a1 | Stack Pointer (callee-saved) |
| jmp_buf[2] - jmp_buf[5] | a12 - a15 | Callee-saved |
所以这段代码也就不难理解了:
1 | #define COCO_PATCHCTX(coco, buf, func, stack, a0) \ |
分别是把 buf[0] 和 buf[1] 改成 coco_main 和 我们为协程新申请的栈。
其他代码基本上是 copy coco 的,详细的可以看我 github:
https://github.com/zwh8800/nodemcu-firmware/commit/1f31aa32901f07b6414c0471eb19f7bdd44d93a6
[EOF] 基本上这次移植涉及到的内容就这些,完。