ioctl函数传统上用于哪些不适合归入其他精细定义类别的特性的系统接口. 虽然POSIX一直在致力于创造特殊函数来取代ioctl函数, 但目前来说大多数网络编程相关的特性还需要用ioctl来实现. 特别是用于网络管理方面的相当之多(如设置ip, 获取接口, 访问路由表, 访问arp).
原型:
1 2 3 #include <sys/ioctl.h> int ioctl (int d, int request, ... )
ioctl的具体用法就不说了, 熟悉linux编程的都或多或少用过. 现在具体说下在网络编程下request的可选值和对应arg指向的的数据类型(在网络编程中arg是一个指针, 下面给出的数据类型都是这个指针要指向的类型).
总结一下的话就是:
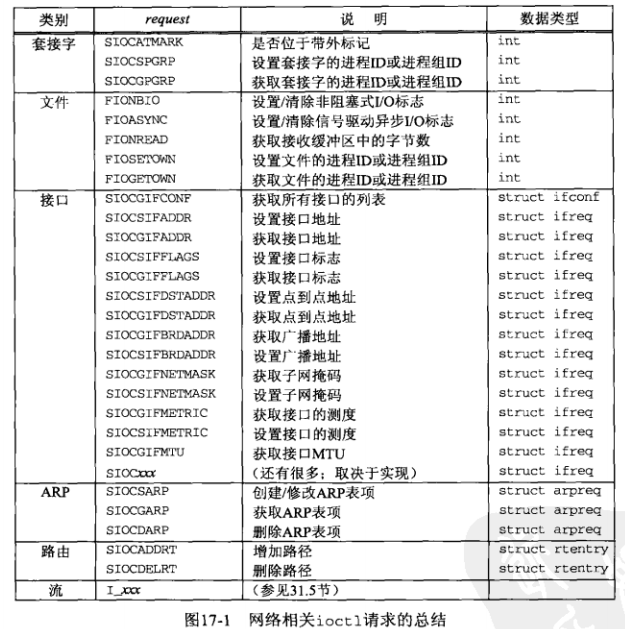
除了文件相关的请求, 其他网络相关的都是SIOC为前缀 (貌似是socket io control?).
设置的请求在前缀后面跟一个S , 获取的请求在后面跟一个G .
接口请求在SIOC[G/S]后面都跟一个IF (interface).
接口请求除了SIOCGIFCONF(获取接口列表)的参数是struct ifconf 以外, 其他所有的都是struct ifreq .
arp请求的参数都是struct arpreq .
路由的请求都是struct rtentry (route entry).
下面重点学习一下接口请求:
接口请求除了上面图上的, 还有很多. 具体的可以去参考ioctl_list(2)中. 文章最下面也有一个表, 有所有的接口相关的request.
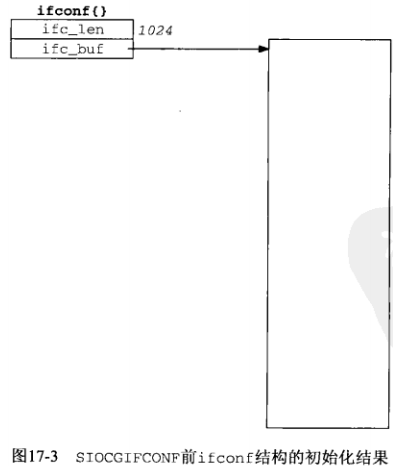
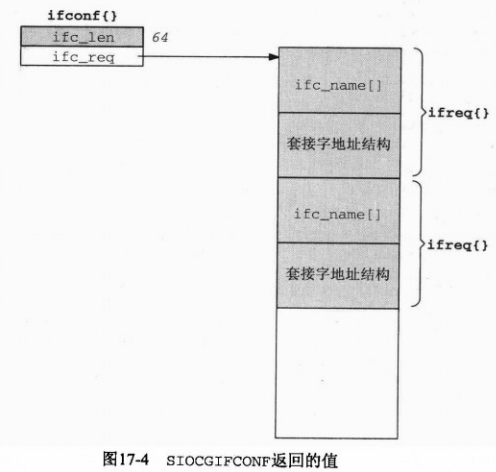
一般情况下, 进行网络配置时, 都会先获取所有网络接口列表, 从内核获取接口列表使用SIOCGIFCONF请求完成. 它会用到struct ifconf结构, 而ifconf结构又会用到ifreq结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 struct ifreq { # define IFHWADDRLEN 6 # define IFNAMSIZ IF_NAMESIZE union { char ifrn_name[IFNAMSIZ]; } ifr_ifrn; union { struct sockaddr ifru_addr ; struct sockaddr ifru_dstaddr ; struct sockaddr ifru_broadaddr ; struct sockaddr ifru_netmask ; struct sockaddr ifru_hwaddr ; short int ifru_flags; int ifru_ivalue; int ifru_mtu; struct ifmap ifru_map ; char ifru_slave[IFNAMSIZ]; char ifru_newname[IFNAMSIZ]; __caddr_t ifru_data; } ifr_ifru; }; # define ifr_name ifr_ifrn.ifrn_name # define ifr_hwaddr ifr_ifru.ifru_hwaddr # define ifr_addr ifr_ifru.ifru_addr # define ifr_dstaddr ifr_ifru.ifru_dstaddr # define ifr_broadaddr ifr_ifru.ifru_broadaddr # define ifr_netmask ifr_ifru.ifru_netmask # define ifr_flags ifr_ifru.ifru_flags # define ifr_metric ifr_ifru.ifru_ivalue # define ifr_mtu ifr_ifru.ifru_mtu # define ifr_map ifr_ifru.ifru_map # define ifr_slave ifr_ifru.ifru_slave # define ifr_data ifr_ifru.ifru_data # define ifr_ifindex ifr_ifru.ifru_ivalue # define ifr_bandwidth ifr_ifru.ifru_ivalue # define ifr_qlen ifr_ifru.ifru_ivalue # define ifr_newname ifr_ifru.ifru_newname struct ifconf { int ifc_len; union { __caddr_t ifcu_buf; struct ifreq *ifcu_req ; } ifc_ifcu; }; # define ifc_buf ifc_ifcu.ifcu_buf # define ifc_req ifc_ifcu.ifcu_req
另外给一个《unix网络编程》上的图:
看起来很复杂, 实际上分开看就不很复杂.
先看ifconf结构, 其实只有两个成员 , 一个是ifc_len , 一个是ifc_ifcu , 这是一个联合所以名字以u结尾, 但是我们不会直接用ifc_ifcu, 直接用的话会很长很麻烦, 而是用下面定义的两个宏, ifc_buf和ifc_req . 当想使用联合的ifcu_buf时, 只需要写ifc.ifc_buf即可, 否则需要写ifc.ifc_ifcu.ifcu_buf. 同理, ifreq也是这样设计的.
为什么要这样设计呢? 因为这个ifreq结构体需要供多个request使用, 当你请求获取ip地址时, 需要存在ifr_addr中, 当你获取子网掩码时需要存在ifr_netmask中, 但是因为需要保存在同一个结构中, 所以用联合比较方便(而且节省空间).
现在继续看ifconf结构, 可以看到, 两个成员成员一 ifc_len为缓冲区长度, 成员二 ifc_buf(既ifc_req)是一个指针, 当调用ioctl(sock, SIOCGIFCONF, &ifc)之前, 需要把成员二当成ifc_buf, 既把它当成一个缓冲区, 所以我们需要自己申请出缓冲区空间, 并且把缓冲区的大小保存在ifc_len中. 当调用之后, 内核会把所有的接口信息保存在我们刚刚申请的ifc_buf缓冲区中. 此时, 缓冲区中的数据是有意义的了, 所以我们应当把成员二当成ifc_req(既当成一个指向struct ifreq的指针), 它指向一个ifreq结构数组, 保存着所有的接口信息. 同时, ifc_len也被更新, 保存着更改之后ifc_req的大小.
上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <net/if.h> #include <sys/ioctl.h> #include <sys/socket.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #define BUF_SIZE 1024 int main () int sock; struct ifconf ifc ; struct ifreq * pifr ; int n, i; if ((sock = socket(AF_INET, SOCK_DGRAM, 0 )) == -1 ) { perror("socket" ); exit (errno); } bzero(&ifc, sizeof (ifc)); if ((ifc.ifc_buf = malloc (BUF_SIZE)) == NULL ) { perror("malloc" ); exit (errno); } ifc.ifc_len = BUF_SIZE; if (ioctl(sock, SIOCGIFCONF, &ifc) == -1 ) { perror("ioctl" ); exit (errno); } n = ifc.ifc_len / sizeof (struct ifreq); printf ("%d interfaces on your computer\n" , n); for (i = 0 , pifr = ifc.ifc_req; i < n; ++i, ++pifr) printf ("\tinterface %d : %s\n" , i, pifr->ifr_name); free (ifc.ifc_buf); return 0 ; }
不用解释了吧, 先申请ifc.ifc_buf的空间, 调用ioctl之后, ifc.ifc_buf被填充, 然后把它当做ifc_req来读取.
看图会更清晰:
ioctl前:
ioctl后:
剩下的使用ifreq的用法就简单了, 直接上代码吧:
这个是获取接口ip地址的函数, 可以和上面那个配合使用(在循环中输出接口ip)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <arpa/inet.h> char * getifaddr (int sock, const char * ifname, char * addr, size_t n) struct ifreq ifr ; struct sockaddr_in *paddr ; bzero(&ifr, sizeof (ifr)); strncpy (ifr.ifr_name, ifname, IFNAMSIZ); if (ioctl(sock, SIOCGIFADDR, &ifr) == -1 ) { perror("ioctl" ); return NULL ; } paddr = (struct sockaddr_in*)&ifr.ifr_addr; if (inet_ntop(AF_INET, &paddr->sin_addr, addr, n) == NULL ) { perror("inet_ntop" ); return NULL ; } return addr; }
这个是设置ip的实用程序(需要root)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <net/if.h> #include <sys/ioctl.h> #include <sys/socket.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #define BUF_SIZE 1024 #include <arpa/inet.h> int main (int argc, char * argv[]) int sock; struct ifreq ifr ; struct sockaddr_in *sin ; if (argc != 3 ) { exit (1 ); } bzero(&ifr, sizeof (ifr)); strncpy (ifr.ifr_name, argv[1 ], IFNAMSIZ); sin = (struct sockaddr_in*)&ifr.ifr_addr; sin ->sin_family = AF_INET; if (inet_pton(AF_INET, argv[2 ], &sin ->sin_addr) == -1 ) { perror("inet_pton" ); exit (errno); } if ((sock = socket(AF_INET, SOCK_DGRAM, 0 )) == -1 ) { perror("socket" ); exit (errno); } if (ioctl(sock, SIOCSIFADDR, &ifr) == -1 ) { perror("ioctl" ); exit (errno); } return 0 ; }
附:所有接口相关request
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 0x00008910 SIOCGIFNAME char []0x00008911 SIOCSIFLINK void 0x00008912 SIOCGIFCONF struct ifconf * // MORE // I -O 0x00008913 SIOCGIFFLAGS struct ifreq * // I -O 0x00008914 SIOCSIFFLAGS const struct ifreq * 0x00008915 SIOCGIFADDR struct ifreq * // I -O 0x00008916 SIOCSIFADDR const struct ifreq * 0x00008917 SIOCGIFDSTADDR struct ifreq * // I -O 0x00008918 SIOCSIFDSTADDR const struct ifreq * 0x00008919 SIOCGIFBRDADDR struct ifreq * // I -O 0x0000891A SIOCSIFBRDADDR const struct ifreq * 0x0000891B SIOCGIFNETMASK struct ifreq * // I -O 0x0000891C SIOCSIFNETMASK const struct ifreq * 0x0000891D SIOCGIFMETRIC struct ifreq * // I -O 0x0000891E SIOCSIFMETRIC const struct ifreq * 0x0000891F SIOCGIFMEM struct ifreq * // I -O 0x00008920 SIOCSIFMEM const struct ifreq * 0x00008921 SIOCGIFMTU struct ifreq * // I -O 0x00008922 SIOCSIFMTU const struct ifreq * 0x00008923 OLD_SIOCGIFHWADDR struct ifreq * // I -O 0x00008924 SIOCSIFHWADDR const struct ifreq * // MORE 0x00008925 SIOCGIFENCAP int * 0x00008926 SIOCSIFENCAP const int * 0x00008927 SIOCGIFHWADDR struct ifreq * // I -O 0x00008929 SIOCGIFSLAVE void 0x00008930 SIOCSIFSLAVE void 0x00008970 SIOCGIFMAP struct ifreq * // I -O 0x00008971 SIOCSIFMAP const struct ifreq *