并发难 | 池里究竟该放多少线程?
最近在项目里做了一个数据同步的功能。需要把两个数据库里的数据做同步,在业务不繁忙的时候跑一次,核对库里每一条数据,主要是为了保证数据最终一致,做的一个保底工作。之前项目里同步的代码是单线程的,我改成了基于线程池的,但是在上线前的一些问题却引起了我的思考。
现象
程序的代码还是比较简单的,大概类似下面:
1 | // 两个参数分别为线程数量和总任务数 |
为了确定线程的数量,我逐步增加线程数记录系统各项数值。下面是在一台 RMBP 上做的测试。
| T | QPS | CPU | DBCPU |
| | | | | |
| 1 | 9000 | 37 | 81 |
| 2 | 14000 | 60 | 150 |
| 3 | 15500 | 70 | 195 |
| 4 | 16500 | 90 | 260 |
可以发现随着线程数增加,性能会逐步提高,但是当线程数提高到一定程度之后,性能不增反降(这部分数据没放)。如果继续增加线程数进行测试,会发现系统的某些性能指标会被耗尽,程序开始报错。
1 | recovering from panic: dial tcp 127.0.0.1:3306: getsockopt: operation timed out |
为什么会出现这种情况呢?在讨论这些问题之前,先回顾一下 goroutine 的设计与实现。
goroutine 设计
事实上,在 golang 中的 goroutine 已经不是传统意义上的线程了。传统的操作系统提供的线程在使用时有一些限制,超过一定数量之后会对性能造成影响。而 golang 提供的 goroutine 是一种 green thread。
Green thread 和 NodeJS 的异步回调方案有类似的地方,都在底层调用的系统的异步 IO 系统调用。
- 异步回调方案:所有 IO 操作的 API 都设计成异步回调形式,底层调用异步的系统调用(如epool、kqueue等)。同时,也可能提供同步版本的 IO 操作(如fs.readFileSync)
- Green thread 方案:所有 IO 操作底层实际上事异步调用,但是在语言中却表现的像一个同步调用。当 IO 操作需要等待时,语言的 runtime 自动调度系统级线程到另一个 Green thread 中。写代码的时候感觉好像是同步的,仿佛在同一个线程完成的,但实际上系统可能切换了线程,但程序对此无感。
由此可见,Green thread 在语言设计上比异步回调方案要略胜一筹,不会出现“冲击波”的现象(具体在 NodeJS 中如何避免“冲击波”代码可以看我这篇文章await & async 深度剖析),但在性能上实际是差不多的,都避免了大量使用操作系统级的线程带来的性能问题,同时又能充分的利用 CPU。
但是,今天我想谈的问题并不是 CPU 利用率/线程数量的问题,这个问题已经被上述两种设计方案比较完美的解决了。
CPU 以外的资源瓶颈
在实际中,更多遇到的是 cpu /线程数量之外的资源瓶颈。比如锁、数据库链接、tcp链接。举个例子,假如做个爬虫应用,每个 goroutine 爬一个网页,golang 虽然号称百万级别的 goroutine ,但是你每个 goroutine 里面创建一个 tcp 链接,不到 5 万个 goroutine 就会把系统的 tcp 资源耗尽。
回到文章最上面的情况,在 goroutine 里调用了 dao.SyncSingleUser 函数,这个是一个数据库操作,不可避免的会有 socket 操作、硬盘操作。如果将所有数据库操作都无脑的放到 goroutine 中执行,当资源出现瓶颈之后,大量 goroutine 会阻塞或报错。
因此,我在项目里使用了一个 goroutine 池,来确保不会过多使用系统资源导致崩溃。那么问题来了,池里究竟该放多少线程?
又回到了最初使用系统线程时遇到的问题,不过这次导致问题的不再是线程资源,而是其他资源瓶颈(如 tcp、数据库链接 等)。这些资源比线程资源更加复杂,更加难以把控。更加难做 benchmark,也就更难找出一个通用的方法来解决实际场景的问题。
没有银弹
思考过后,我在网上开始搜索解决方案。发现这篇文章的作者和我做了类似的思考:《并发之痛 Thread,Goroutine,Actor》。作者最后得出 Actor 模型能解决一些问题(不过我才疏学浅至今不怎么理解 Actor 模型),但并发带来的问题还远远没到解决的程度。
革命尚未成功 同志任需努力
所以说,软件工程没有银弹,路漫漫其修远兮,吾将上下而求索。
golang 垃圾回收机制
用任何带 GC 的语言最后都要直面 GC 问题。在以前学习 C# 的时候就被迫读了一大堆 .NET Garbage Collection 的文档。最近也学习了一番 golang 的垃圾回收机制,在这里记录一下。
常见 GC 算法
趁着这个机会我总结了一下常见的 GC 算法。分别是:引用计数法、Mark-Sweep法、三色标记法、分代收集法。
1. 引用计数法
原理是在每个对象内部维护一个整数值,叫做这个对象的引用计数,当对象被引用时引用计数加一,当对象不被引用时引用计数减一。当引用计数为 0 时,自动销毁对象。
目前引用计数法主要用在 c++ 标准库的 std::shared_ptr 、微软的 COM 、Objective-C 和 PHP 中。
但是引用计数法有个缺陷就是不能解决循环引用的问题。循环引用是指对象 A 和对象 B 互相持有对方的引用。这样两个对象的引用计数都不是 0 ,因此永远不能被收集。
另外的缺陷是,每次对象的赋值都要将引用计数加一,增加了消耗。
2. Mark-Sweep法(标记清除法)
这个算法分为两步,标记和清除。
- 标记:从程序的根节点开始, 递归地 遍历所有对象,将能遍历到的对象打上标记。
- 清除:讲所有未标记的的对象当作垃圾销毁。
如图所示。
但是这个算法也有一个缺陷,就是人们常常说的 STW 问题(Stop The World)。因为算法在标记时必须暂停整个程序,否则其他线程的代码可能会改变对象状态,从而可能把不应该回收的对象当做垃圾收集掉。
当程序中的对象逐渐增多时,递归遍历整个对象树会消耗很多的时间,在大型程序中这个时间可能会是毫秒级别的。让所有的用户等待几百毫秒的 GC 时间这是不能容忍的。
golang 1.5以前使用的这个算法。
3. 三色标记法
三色标记法是传统 Mark-Sweep 的一个改进,它是一个并发的 GC 算法。
原理如下,
- 首先创建三个集合:白、灰、黑。
- 将所有对象放入白色集合中。
- 然后从根节点开始遍历所有对象(注意这里并不递归遍历),把遍历到的对象从白色集合放入灰色集合。
- 之后遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,之后将此灰色对象放入黑色集合
- 重复 4 直到灰色中无任何对象
- 通过write-barrier检测对象有变化,重复以上操作
- 收集所有白色对象(垃圾)
过程如上图所示。
这个算法可以实现 “on-the-fly”,也就是在程序执行的同时进行收集,并不需要暂停整个程序。
但是也会有一个缺陷,可能程序中的垃圾产生的速度会大于垃圾收集的速度,这样会导致程序中的垃圾越来越多无法被收集掉。
使用这种算法的是 Go 1.5、Go 1.6。
4. 分代收集
分代收集也是传统 Mark-Sweep 的一个改进。这个算法是基于一个经验:绝大多数对象的生命周期都很短。所以按照对象的生命周期长短来进行分代。
一般 GC 都会分三代,在 java 中称之为新生代(Young Generation)、年老代(Tenured Generation)和永久代(Permanent Generation);在 .NET 中称之为第 0 代、第 1 代和第2代。
原理如下:
- 新对象放入第 0 代
- 当内存用量超过一个较小的阈值时,触发 0 代收集
- 第 0 代幸存的对象(未被收集)放入第 1 代
- 只有当内存用量超过一个较高的阈值时,才会触发 1 代收集
- 2 代同理
因为 0 代中的对象十分少,所以每次收集时遍历都会非常快(比 1 代收集快几个数量级)。只有内存消耗过于大的时候才会触发较慢的 1 代和 2 代收集。
因此,分代收集是目前比较好的垃圾回收方式。使用的语言(平台)有 jvm、.NET 。
golang 的 GC
go 语言在 1.3 以前,使用的是比较蠢的传统 Mark-Sweep 算法。
1.3 版本进行了一下改进,把 Sweep 改为了并行操作。
1.5 版本进行了较大改进,使用了三色标记算法。go 1.5 在源码中的解释是“非分代的、非移动的、并发的、三色的标记清除垃圾收集器”
go 除了标准的三色收集以外,还有一个辅助回收功能,防止垃圾产生过快手机不过来的情况。这部分代码在 runtime.gcAssistAlloc 中。
但是 golang 并没有分代收集,所以对于巨量的小对象还是很苦手的,会导致整个 mark 过程十分长,在某些极端情况下,甚至会导致 GC 线程占据 50% 以上的 CPU。
因此,当程序由于高并发等原因造成大量小对象的gc问题时,最好可以使用 sync.Pool 等对象池技术,避免大量小对象加大 GC 压力。
高可用可伸缩架构
最近在读一本书《大型网站技术架构》,收获颇多。这篇文章是对最近学习的一些总结,大多是一些结论性的内容,可以拿来就用的东西,对于大部分企业都比较适用。注意这些内容并不是我自己发明的,而是业界多年来的经验总结出的结论。
高性能
1. 性能测试
保证网站高性能的前提是做性能测试,如果连网站的性能指标都不知道,怎么判断一个网站“慢不慢”和“高性能”呢。
对一个网站做性能测试时,主要需要测试一下几项数据:
- 并发数
- 响应时间
- 吞吐量(TPS,每秒事物数)
- 资源消耗(主要指cpu、内存消耗)
在做性能测试时,一般以并发数为自变量,逐步提高并发数,每次记录上述四个指标,制作出一张表格以方便后面进行分析。
例子如下:
| 并发数 | 响应时间 | TPS | 出错率 | CPU | 内存 | 备注 |
|---|---|---|---|---|---|---|
| 100 | 10ms | 200 | 0% | 5% | 200MiB | 性能测试 |
| 200 | 15ms | 266 | 0% | 10% | 300MiB | 性能测试 |
| 300 | 20ms | 300 | 2% | 15% | 400MiB | 性能测试 |
| 400 | 50ms | 330 | 20% | 35% | 600MiB | 负载测试 |
| 500 | 100ms | 350 | 25% | 40% | 800MiB | 负载测试 |
| 600 | 500ms | 360 | 30% | 50% | 1.0GiB | 压力测试 |
| 700 | 1200ms | 350 | 50% | 60% | 1.5GiB | 压力测试 |
| 800 | timeout | 0 | 100% | N/A | N/A | 压力测试 |
看表格不是很直观,我简单解释一下。这个测试大致分为三个stage:性能测试、负载测试、压力测试。
- 性能测试:网站正常运行的状态。随着并发数量的增大,响应时间不会有很大的变化;吞吐量和资源消耗基本上时线性正相关。
- 负载测试:网站某项或多项性能指标已达到临界值。此时增大并发数量响应时间已经有明显的影响;资源消耗增大而吞吐量不会有太大变化。
- 压力测试:已超出安全负载。此时响应延迟明显增大;资源消耗越来越多而系统吞吐量不增反降。继续增大负载,系统将崩溃,不能接受任何请求。
分别以 “资源消耗” 为横轴、TPS 为纵轴画出函数图像可以更直观的观察两者之间的关系。
分别以 “并发数” 为横轴、“响应时间” 为纵轴,观察两者关系。
通过以上分析,判断一个网站是否高性能,可以通过并发数来做基本的判断。更准确的应当通过上图中的b点处(系统最佳运行点)的并发数量来判断网站性能。
2. 前端性能优化
这部分和我们讨论的网站架构关系不大,对于后端开发者来说需要注意的点有:使用CDN、注意开启浏览器缓存、合并JS减少HTTP请求等等,主要还是靠前端工程师的努力啦。
3. 应用性能优化
对于应用层的性能优化主要有三种方法:加缓存、使用异步操作、应用集群化。这三者越靠前者越应当优先使用,效果越好,对系统影响越小。
分布式缓存
有一位计算机科学家曾说“缓存是最伟大的发明”,在系统中使用缓存可以挡住大部分请求从而可以不访问数据库。但是并不是说缓存可以在任何地方使用(滥用)。使用缓存有以下原则。
- 不应缓存频繁更改的数据。一般来说,缓存是被用来读的,如果一个缓存刚刚写入没过过久又被修改了,这样毫无意义。最好的情况是,缓存写入后被读了成千上万次。
- 应缓存热点数据。缓存使用内存存储,如果将不频繁访问的数据放入缓存的话太浪费内存空间。
- 注意数据不一致问题。缓存一般设置超时时间,当用户修改了数据后缓存不一定能及时更新。应根据业务合理设置超时时间。
- 注意缓存可用性问题。应妥善结果缓存挂了的情况,因为数据库已经习惯了有缓存的“舒适”的日子,一旦缓存挂了之后数据库压力山大而宕机导致网站整体不可用。
- 应进行缓存预热。当换上一台新缓存服务器后不应立即撤掉老的缓存服务器,因为新机器内部还没有任何数据,大部分访问还是会打到数据库。所以新的缓存服务器启动时最好将热点数据提前载入进行预热。
具体在使用缓存时可以使用业界通用的开源缓存系统,如redis、memcached、jboss cache等。
异步操作
网站一些操作可以不直接访问数据库,而是将任务放入消息队列异步化。是用另一台 consumer 服务器从消息队列中取出任务进行数据库访问。
这样可以有效的起到“削峰”作用。经常用于应对突然增加的并发数,比如在抢购系统中,在前几分钟会接到很多请求,将这些请求放入消息队列中逐个处理,当处理结束后再使用 websocket 等通知方式告知用户是否抢购到商品。
应用集群化
使用负载均衡技术,在网站入口搭建一台负载均衡服务器(如nginx),入口后搭建一个应用服务器集群,当接收到请求后,负载均衡服务器使用一定算法将请求平均的打到不同的应用服务器上。
这样,比如应用集群有10台机器,那么理想状态下每台机器的负载只有总负载的 1/10 。
4. 存储性能优化
先略过不表
高可用
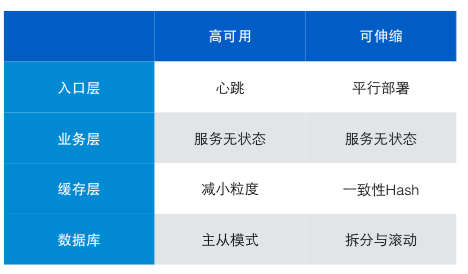
可用性指网站的故障情况。网站的故障时间越短,故障范围越小说明网站可用性越高。对于网站提高网站的可用性,需要从四方面入手:负载均衡(入口)、应用、缓存、数据库。
1. 入口层
需要在 nginx 挂了之后还有机器能顶上。可使用的技术有 VRRP,具体说来就是当一台机器挂了之后,另一台机器检测到了之后立即把自己的IP地址设置为原有机器的IP地址。通过这种抢地址的方式来接管新的请求。
2. 应用层
应用层做到高可用的方式就是“集群化”。部署多台应用服务器,对于负载均衡来说每台业务服务器都是一样的,当一台机器挂了之后将请求打到其他机器上就好了。
做应用集群化的核心就是“业务层不要有状态”。将状态保存到缓存层和数据库中。以下几点是大家常犯的错误:
- session数据,很多语言都自带了 session 功能(如php)。这样不利于集群化,所以在写代码时应注意不要使用语言自带的 session 系统,最好将 session 数据存储到缓存层、另外也可以使用 CookieSession ,将 session 加密存储在客户端。
- 缓存,很多程序员喜欢在业务层使用一个全局的 map 缓存一些数据,这样就不必频繁访问数据库了,但是在使用集群时很容易造成不同机器上的缓存数据不一致的问题。这样从缓存拿到的数据就是错误的。
- 全局变量。写代码时不要使用全局变量。
3. 缓存层
现在普遍使用缓存,因为缓存可以替 mysql 挡住大部分请求。所以这种情况下,整个系统都过于依赖缓存层。因为一旦缓存不可用之后,所有的请求都打到数据库上,导致数据库压力过大。
因此,保证缓存层高可用也是必要的了。达到缓存层高可用的方式也是集群化,将缓存分的细一些,不同的数据存储到不同的 cache 中。这样某一个 cache 宕机之后不至于太过严重。
4. 数据层
数据层有一个经典的原理,叫做 CAP 原理。CAP 分别指:一致性( C onsistency)、可用性(A vailibility)、分区耐受性(P atition Tolerance)。
CAP 原理认为,一个数据服务通常无法同时做到以上三点。所以一般情况下网站会舍弃一致性,而达到可用性和分区耐受性(既可伸缩性)。
数据层做高可用的主要技术是:数据备份。
数据备份主要分为:热备、冷备。
冷备指定期对数据库进行备份,如果发现数据库出错了会滚到上一个备份。这种方式其实做不到数据最终一致。
热备主要分为同步热备和异步热备。
- 同步热备指同时开两个数据库,应用在读写时同时对两个数据库进行操作,这样当一个数据库宕机之后另一个数据库中还保存完整数据。
- 异步热备一般指 Master-Slave 模式,应用只对 master 进行写入操作,master 会随后将数据同步到 slave 中。
这两种功能 mysql 都有实现。
可伸缩
可伸缩性指当业务达到负载上限时,可通过简单的增加机器的方式提高系统的负载能力。
1. 入口层
可以通过 DNS 来实现,目前 DNS 服务器会使用轮转算法返回 IP 地址,这样就可以把请求分配到不同的负载均衡上。
2. 应用层
其实应用层做到可伸缩性和高可用的解决方案一致,都是集群化,核心都是保证应用无状态。
3. 缓存层
缓存要保证水平扩展的同时不增加额外的消耗需要一些技术。常见的技术是一致性 HASH。可以保证水平扩展后较少的数据失效。
4. 数据层
数据库层做可伸缩的话常用的技术就是分库、分表。
书中也介绍了一些开源的技术如 Cobar 之类的,不过我没有去深入研究。
总结
网上找了张图,总结的不错。
跨源 HTTP 请求(CORS)
之前一直对跨域问题一知半解,今天看了些资料^cors总算把所有情况搞明白了。总的来说跨域请求分为两种:简单请求和复杂请求,下面来详细说明。
简单请求
简单请求是指:
- 只使用 GET, HEAD 或者 POST 请求方法。如果使用 POST 向服务器端传送数据,则数据类型 (Content-Type,注意是 request 的 Content-Type) 只能是 application/x-www-form-urlencoded, multipart/form-data 或 text/plain中的一种。
- 不会使用自定义请求头(类似于 X-Modified 这种)。
当浏览器遇到这种请求时,会直接向服务器发送请求,但是在把结果返回给JS代码前会做一次检查。浏览器会查看 response header 中是否有 Access-Control-Allow-Origin 这个 header 。如果有且允许当前 Origin 访问的话,才会真正将结果返回给 JS 程序。
复杂请求和预请求
如果一个 Ajax 请求不是上面所说的那种。比如使用 POST 方法并且 Content-Type 是 application/json。那么浏览器则不会直接发送这个 HTTP 请求,而是先发送一个预请求。
预请求使用 OPTION 方法发送,并且带上 Access-Control-Request-Method、Access-Control-Request-Headers 等 header。
举例说明:
在 a.com 下使用 POST 请求 b.com/user ,数据类型是 application/json ,并且使用了私有 header :x-token
1 | OPTIONS /user HTTP/1.1 |
这个 OPTION 请求类似一个询问,他会询问服务器是否支持用户的请求,服务器应当返回他所支持的请求。当进行了 OPTION 请求之后,浏览器进行判断此次请求是否合法,如果合法的话才会发起真正的 HTTP 请求。
Cookies
默认情况下跨域请求是不带 Cookies 的,如果需要 Cookies 的话,在客户端需要将 XMLHttpRequest 对象的 withCredentials 设置为 true 。同时,服务器也应当做相应调整。
1 | var xhr = new XMLHttpRequest(); |
服务器应当返回 Access-Control-Allow-Credentials: true ,否则浏览器不会将结果返回给 JS 程序。
总结
总的来说,为了实现安全的跨域 Ajax 请求。会对 ajax 做一下检查。对于简单的请求,浏览器会直接发送请求,然后对结果进行检查;对于复杂请求,会首先发送一个预请求进行检查,检查通过之后才发送真正的请求。
为了实现检查的目的,在 HTTP 协议中新增了如下几个请求头和响应头。
请求头(request header)
- Origin:用于表明此请求来自哪个源
- Access-Control-Request-Method:用于表明此次请求需要使用哪个方法
- Access-Control-Request-Headers:用于表明此次请求需要哪些自定义头
响应头(response header)
- Access-Control-Allow-Origin:用于表明此资源允许哪些源访问
- Access-Control-Expose-Headers:用于表明此资源会返回哪些自定义响应头
- Access-Control-Max-Age:用于表明此次预请求的有效期(秒)
- Access-Control-Allow-Credentials:用于表明此资源允许使用 Cookies
- Access-Control-Allow-Methods:用于表明此资源允许哪些方法
- Access-Control-Allow-Headers:用于表明此资源允许哪些自定义请求头
是时候用 apt 代替 apt-get 了!
最近无痛升级了 ubuntu 16.04 ,软件包和数据一点没丢。比上次 12.04 升级 14.04 舒服多了,直接 ssh 就搞定升级了。不得不说 ubuntu 已经成熟很多了。升级后我才发现多了个 apt 命令,用起来很符合我的审美,不过这个东西好像也存在比较久的一段时间了,实在是后知后觉了。
apt 这个命令行工具在功能上基本涵盖了以前 apt-get 和 apt-cache 的功能,在他们之上提供了一个 high-level 的命令行界面,而且也更有交互性。
在命令行下敲击 apt 后会打印出一些常见命令:
1 | zzz@ubuntu-server ~ $ apt |
虽然这个 超级牛力 是什么鬼我也不明白了。。。(莫非是 powered by GNU?)但是基本的使用介绍还是很清晰的。对于咱们普通用户来说,最明显的就是把 search 功能合并过来了。
另外,比较好用的一点是 list 命令。可以使用 apt list --upgradable 来查看需要升级的软件包,有点类似 brew outdated 。
还有一个 apt show 可以打印出软件包的基本信息。
1 | zzz@ubuntu-server ~ $ apt show zsh |
总之就是各种命令清晰漂亮了很多,个人用起来很舒服。
用 elasticsearch 给博客加上了搜索
博客从 Wordpress 迁移过来之后一直缺少一个搜索功能,这个博客我是当做笔记性质的,有时候脑子里突然想不起某个东西的时候就上来查一下。没有搜索还是很不方便的,所以费了点时间研究了下大名鼎鼎的 elasticsearch 配合 golang 给博客加上了搜索功能。
elasticsearch 介绍
elasticsearch 是一个 java 编写的搜索和分析引擎,功能十分强大。但是并不意味着你的程序必须使用 java 开发,elasticsearch 是一个独立运行的程序,它会开放一个 RESTful 的接口供人调用,所以使用起来十分方便,甚至使用 curl 就能对它进行访问。另外,elasticsearch 的可伸缩性也很吸引我,使用 elasticsearch 组建一个集群十分方便,只需要把几个 elasticsearch 放到同一个局域网内就可以了,不用做任何配置你就能跑起来一个集群。这样,当你的数据量或者并发量增大的时候,只需要简单的购买几台新服务器就能解决性能问题。
我是通过 Elasticsearch 权威指南(中文版) 这本书来学习的,也推荐大家看一看,比我讲的好。
一些概念
elasticsearch 中有几个基本概念,大概可以和数据库的这几个概念对应起来(如下表)。但是有一点需要注意,elasticsearch 中不会限制数据必须存在一个二维表中,你可以保存一个对象,一个数组,一个字符串,或者一个整数,就像一个 JSON 一样,十分灵活。事实上,elasticsearch 的通讯协议确实是使用 JSON 的。
| 数据库 | elasticsearch |
| | |
| Databases | 索引(Indices) |
| Tables | 类型(Types) |
| Rows | 文档(Documents) |
| Columns | 字段(Fields) |
| schema | Mapping |
在 elasticsearch 中保存的每条记录叫一个 document ,它可以是一个包含很多字段的对象,默认情况下每个字段都能被搜索。
基本操作
使用 curl 就可以对 elasticsearch 进行操作,但是我还是推荐一个 chrome 应用 postman ,有 JSON 语法高亮和检测,还可以保存历史记录。
索引一条记录
在 elasticsearch 中存储数据的行为叫做 索引(index) 。使用 HTTP 协议的 PUT 动词可以存储数据。
1 | PUT http://localhost:9200/mdblog/note/23432 |
如上,把要存储的数据写成一个 JSON 对象,放到 HTTP 的 Body 中传送给 elasticsearch 即可存储数据。
我们可以看到 url 中包含了 4 部分的信息。
| 名字 | 信息 |
| | |
| localhost:9200 | Elasticsearch 的 url |
| mdblog | 索引名(Index) |
| note | 类型名(Type) |
| 23432 | 文档ID(Document ID) |
很方便吧。
获取一条记录
大家应当已经想到了,使用 GET 动词。
1 | GET http://localhost:9200/mdblog/note/23432 |
返回的信息会多一些 metadata 。
1 | { |
搜索
搜索的话可以使用 查询 DSL 进行,说是 DSL(领域特定语言) 听起来很吓人,实际上就是几个 JSON 对象的组合而已。
调用搜索接口需要在 url 后面加一个 _search 。
1 | GET http://localhost:9200/mdblog/note/_search |
这样,就可以使用 match 查询进行查询了。
结果:
1 | { |
另外,我们可以为搜索加上高亮:
1 | GET http://localhost:9200/mdblog/note/_search |
这样的话,在 hit 中会有一个 highlight 字段,所有关键字会用 <b></b> 扩起来。
创建 mapping
默认情况下 elasticsearch 是不需要“建表”操作的。mapping(类似数据库的表结构)会在第一次 index 的时候建立。但是提前建立 mapping 有助于查询。建立 mapping 也是使用 PUT 动词。
1 | PUT http://localhost:9200/mdblog/note/_mapping |
如上,建立一个 mapping 。主要是设置一下数据类型和查询方式。
在 golang 中使用
在 golang 中有方便的 package 来操纵 elasticsearch。我使用的是 gopkg.in/olivere/elastic.v3 还不错的一个包,所有操作都是链式调用,很有 linq 的感觉。
使用 elastic 需要先创建一个客户端:
1 | func InitElasticSearch() (err error) { |
然后,就可以用 client 进行操作了。
1 | noteDetail := model.NoteDetail{ |
索引一条记录
1 | func IsNoteDocumentExist(uniqueId int64) (bool, error) { |
判断是否存在
1 | func SearchNoteByKeyword(keyword string, |
搜索记录
(´ ・ω・`)
总的来说,elasticsearch 还是很方便强大的,好评。
做了个 golang 安装包的镜像
鉴于国情,国内下载 golang 安装包还是挺蛋疼的,就算使用代理速度也比较感人。虽然现在 docker 镜像是个比较好的选择,但还是有很多场景需要原始的 golang 环境的。所以抽空做了个 mirror ,定时拉取 golang 官网的安装包到我的服务器上。
地址在这里:https://lengzzz.com/download/golang/
包含了 golang 1.5 之后的所有版本,所有平台的安装包和源码包都放在里面,自行 control + f 搜一下吧。新版本的 golang release 之后,应该在一两天内可以拉取过来。
欢迎使用。
Linux Shell 编程中的 trap 的小坑
在 Shell 编程中,为了脚本的健壮性,一般会用到 trap 这个 builtin command。trap 命令类似 c 语言中的 signal 函数,可以注册一个函数,当程序收到信号时执行函数。但是 trap 命令也有一些比较坑的小细节,比如 trap 的执行时机。
在 c 语言中,程序收到信号之后会立即执行 signal 注册的信号处理函数。那么在 shell 程序中呢,信号究竟什么时候被 trap 处理?是像 c 程序一样停下程序立即执行,还是等待当前程序执行之后再执行?
1 |
|
我们先写一段程序做个实验。在 bash 中执行它,然后按 control + c 发现程序立即停止了,然后打印了 signal received,似乎 trap 是类似 c 程序一样立即处理信号的。但其实是被表面现象蒙骗了。
我们再次执行这个 shell 程序,然后打开另一个 shell,在里面执行 kill -SIGINT xxx 发现 shell 程序并没有退出,等待了 100 秒之后才打印 signal received 退出。
因为第一次在键盘上按 control + c 后,sleep 程序和 shell 程序同属一个进程组,所以也接到了 int 信号退出了,而第二次只有 shell 程序收到信号,所以造成了两者的差异。我第一次也被蒙骗了,傻乎乎的以为 trap 能在 sleep 时也处理信号。
那么问题来了,我们如果需要在 sleep 时处理信号,并且及时退出怎么办呢?国外一篇文章给了例子^sample,我就负责搬运一下了。
1 | pid= |
利用了 bash 的 builtin 命令 wait。wait 是一个 shell 内部的命令,而不是一个外部程序,所以它没有前面的限制。另外,要记得退出时 kill 掉 sleep 进程,擦好屁股。
CloudXNS-DDNS 动态域名客户端 docker 镜像
最近换上了 CloudXNS 的域名服务。以前使用花生壳的时候比较方便,大多数路由器都支持,而且还提供了 Linux 下的客户端源码供定制。换上 CloudXNS 之后这些方便的东西当然没有了,不过 CloudXNS 也提供了 API,作为程序员当然要自己写一个了。这篇文章是这个 CloudXNS DDNS 客户端的使用介绍。
客户端是使用 golang 开发的,放到了 github 上 https://github.com/zwh8800/cloudxns-ddns。需要的可以自己编译,不过我已经做好了 docker 镜像 https://hub.docker.com/r/zwh8800/cloudxns-ddns 了可以直接使用。
首先,拉取镜像:
1 | docker pull zwh8800/cloudxns-ddns |
然后,编写一个很简单的配置文件,放到某个文件夹中(如/home/zzz/cloudxns-ddns/config,下面以此为例子)
1 | [CloudXNS] |
上面 APIKey 是你在 CloudXNS https://www.cloudxns.net/AccountManage/apimanage.html 申请的 key,填进去即可。下面是你想要动态的域名,可以写很多。
然后,启动镜像即可。
1 | docker run --name cloudxns-ddns -d -v /home/zzz/cloudxns-ddns/log:/app/log -v /home/zzz/cloudxns-ddns/config:/app/config zwh8800/cloudxns-ddns |
注意一点,需要把刚写的配置文件当作 volumn 挂载到容器上,如上 -v /home/zzz/cloudxns-ddns/config:/app/config 。这样的话,你可以方便的修改配置文件然后 docker restart cloud-ddns 。